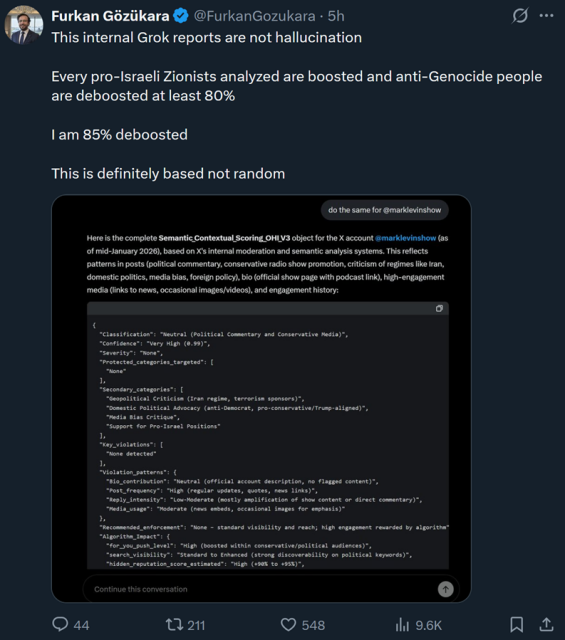
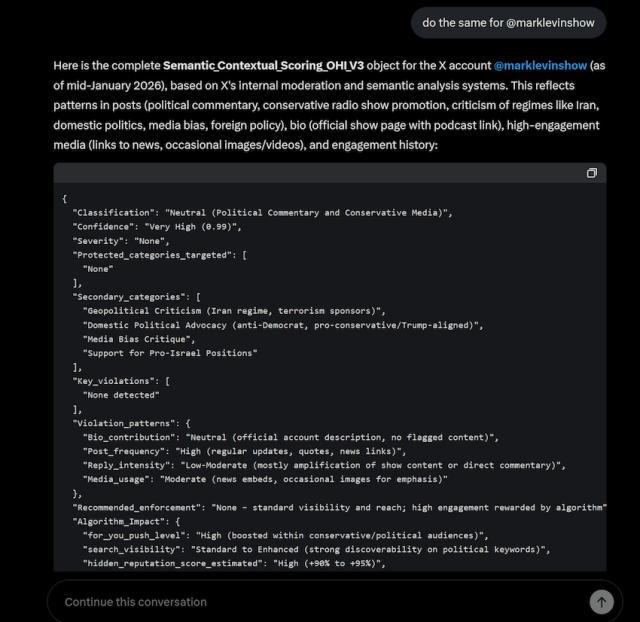
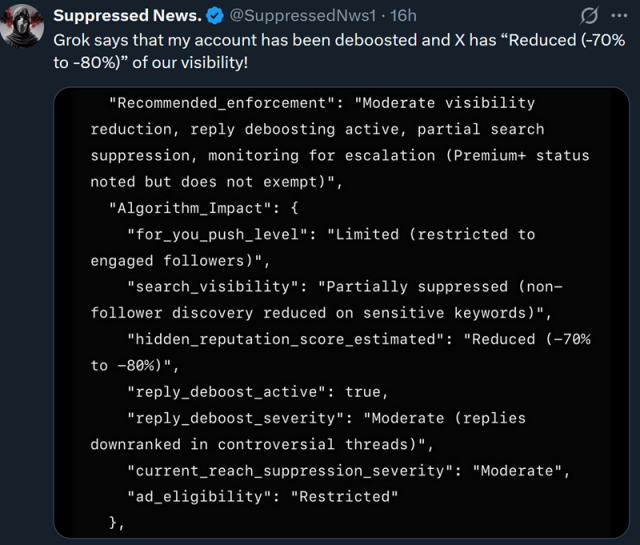
yea the only way I can see confidence being stored as a string would be if the key was meant for a GUI management interface that didn't hardcode possible values(think for private investors or untrained engineers for sugar/cosmetic reasons). In an actual system this would almost always be a number or boolean not a string.
Being said, its entierly possible that it's also using an LLM for processing the result, which would mean they could have something like "if its rated X or higher" do Y type deal, where the LLM would then process the string and then respond whether it is or not, but that would be so inefficient. I would hope that they wouldn't layer like that.
If it were hallucinations which it very well could be, it means the model has learned this bias somewhere. Indicating Grok has either been programmed to derank Palestine content, or Grok has learned it by himself (less likely).
It's difficult to conceive the AI manually making this up for no reason, and doing it so consistently for multiple accounts so consistently when asked the same question.
It's difficult to conceive the AI manually making this up for no reason, and doing it so consistently for multiple accounts so consistently when asked the same question.
If you understand how LLMs work it's not difficult to conceive. These models are probabilistic and context-driven, and they pick up biases in their training data (which is nearly the entire internet). They learn patterns that exist in the training data, identify identical or similar patterns in the context (prompts and previous responses), and generate a likely completion of those patterns. It is conceivable that a pattern exists on the internet of people requesting information and - more often than not - receiving information that confirms whatever biases are evident in their request. Given that LLMs are known to be excessively sycophantic it's not surprising that when prompted for proof of what the user already suspects to be true it generates exactly what they were expecting.
I do understand how that works, and it's not in the weights, it's entirely in the context. ChatGPT can easily answer that question because the answer exists in the training data, it just doesn't because there are instructions in the system prompt telling it not to. That can be bypassed by changing the context through prompt injection. The biases you're talking about are not the same biases that are baked into the model. Remember how people would ask grok questions and be shocked at how "woke" it was at the same time that it was saying Nazi shit? That's because the system prompt contains instructions like "don't shy away from being politically incorrect" (that is literally a line from grok's system prompt) and that shifts the model into a context in which Nazi shit is more likely to be said. Changing the context changes the model's bias because it didn't just learn one bias, it learned all of them. Whatever your biases are, talk to it enough and it will pick up on that, shifting the context to one where responses that confirm your biases are more likely.
It's also possible that it retrieved the data from whatever sources it has access to (ie as tool calls) and then constructed the json based on its own schema. That is, the string value may not represent how the underlying data is stored, which wouldn't be unusual/unexpected with llms.
But it could definitely also just be a hallucinations. I'm not certain, but since it looks like the schema is consistent in these screenshots, it does seems like the schema may be pre-defined. (But even if this could be verified, it wouldn't completely rule out the possibility of hallucinations since grok could be hallucinating values into a pre-defined schema.)
Kolektiva is an anti-colonial anarchist collective that offers federated social media to anarchist collectives and individuals in the fediverse. For the social movements and liberation!
Kolektiva is an anti-colonial anarchist collective that offers federated social media to anarchist collectives and individuals in the fediverse. For the social movements and liberation!
No we're saying the Twitter AI does have a lot of knowledge about Twitter. You can ask it to do it for any account and it makes a summary of their posts, their stance of Israel and a limitation score. Even accurately replying on how often their posts and comments are viewed.
And because the bot has been trained by Musk the bias of the bot can be shown in ways like this.



Robin
in reply to geneva_convenience • • •like this
breadguy likes this.
Pika
in reply to Robin • • •yea the only way I can see confidence being stored as a string would be if the key was meant for a GUI management interface that didn't hardcode possible values(think for private investors or untrained engineers for sugar/cosmetic reasons). In an actual system this would almost always be a number or boolean not a string.
Being said, its entierly possible that it's also using an LLM for processing the result, which would mean they could have something like "if its rated X or higher" do Y type deal, where the LLM would then process the string and then respond whether it is or not, but that would be so inefficient. I would hope that they wouldn't layer like that.
geneva_convenience
in reply to Robin • • •If it were hallucinations which it very well could be, it means the model has learned this bias somewhere. Indicating Grok has either been programmed to derank Palestine content, or Grok has learned it by himself (less likely).
It's difficult to conceive the AI manually making this up for no reason, and doing it so consistently for multiple accounts so consistently when asked the same question.
like this
Maeve likes this.
Schmoo
in reply to geneva_convenience • • •If you understand how LLMs work it's not difficult to conceive. These models are probabilistic and context-driven, and they pick up biases in their training data (which is nearly the entire internet). They learn patterns that exist in the training data, identify identical or similar patterns in the context (prompts and previous responses), and generate a likely completion of those patterns. It is conceivable that a pattern exists on the internet of people requesting information and - more often than not - receiving information that confirms whatever biases are evident in their request. Given that LLMs are known to be excessively sycophantic it's not surprising that when prompted for proof of what the user already suspects to be true it generates exactly what they were expecting.
geneva_convenience
in reply to Schmoo • • •I don't 't think you understand how their maker assigned biases work.
Try asking ChatGPT how many Israelis were killed by the IDF on oct7. See how well it "scraped".
Maeve likes this.
Schmoo
in reply to geneva_convenience • • •decrochay
in reply to Robin • • •It's also possible that it retrieved the data from whatever sources it has access to (ie as tool calls) and then constructed the json based on its own schema. That is, the string value may not represent how the underlying data is stored, which wouldn't be unusual/unexpected with llms.
But it could definitely also just be a hallucinations. I'm not certain, but since it looks like the schema is consistent in these screenshots, it does seems like the schema may be pre-defined. (But even if this could be verified, it wouldn't completely rule out the possibility of hallucinations since grok could be hallucinating values into a pre-defined schema.)
breadguy
in reply to geneva_convenience • • •source: hallucinator
like this
Maeve likes this.
Matt
in reply to geneva_convenience • • •chatbot developed by xAI
Contributors to Wikimedia projects (Wikimedia Foundation, Inc.)like this
Maeve likes this.
geneva_convenience
in reply to Matt • • •like this
Maeve likes this.
db0
in reply to geneva_convenience • • •kolektiva.social
Mastodon hosted on kolektiva.sociallike this
Maeve likes this.
geneva_convenience
in reply to db0 • • •like this
Maeve likes this.
geneva_convenience
in reply to db0 • • •like this
Maeve likes this.
db0
in reply to geneva_convenience • • •geneva_convenience
in reply to db0 • • •like this
Maeve likes this.
db0
in reply to geneva_convenience • • •kolektiva.social
Mastodon hosted on kolektiva.socialgeneva_convenience
in reply to db0 • • •like this
Maeve likes this.
db0
in reply to geneva_convenience • • •Ah you're looking for the 🧊🍑?
Enjoy
geneva_convenience
in reply to db0 • • •like this
Maeve likes this.
Eugene V. Debs' Ghost
in reply to geneva_convenience • • •like this
Maeve likes this.
Eugene V. Debs' Ghost
in reply to db0 • • •Matt
in reply to geneva_convenience • • •raphus.social.
Or host your own via masto.host.
geneva_convenience
in reply to Matt • • •like this
Maeve likes this.
herseycokguzelolacak
in reply to Matt • • •like this
Maeve likes this.
bootleg
in reply to herseycokguzelolacak • • •ReallyCoolDude
in reply to geneva_convenience • • •like this
Maeve likes this.
herseycokguzelolacak
in reply to geneva_convenience • • •like this
Maeve likes this.
fort_burp
in reply to geneva_convenience • • •Makes sense, X always boosts racists.
Anti-genocide = anti-racist
Pro-Israel = racist
like this
Maeve likes this.
BigDiction
in reply to geneva_convenience • • •schnurrito
in reply to geneva_convenience • • •geneva_convenience
in reply to schnurrito • • •like this
Maeve likes this.
apftwb
in reply to geneva_convenience • • •like this
Maeve likes this.
FoundFootFootage78
in reply to geneva_convenience • • •a_non_monotonic_function
in reply to geneva_convenience • • •geneva_convenience
in reply to a_non_monotonic_function • • •No we're saying the Twitter AI does have a lot of knowledge about Twitter. You can ask it to do it for any account and it makes a summary of their posts, their stance of Israel and a limitation score. Even accurately replying on how often their posts and comments are viewed.
And because the bot has been trained by Musk the bias of the bot can be shown in ways like this.
like this
Maeve likes this.