EdgeFusion: On-Device Text-to-Image Generation
Abstract
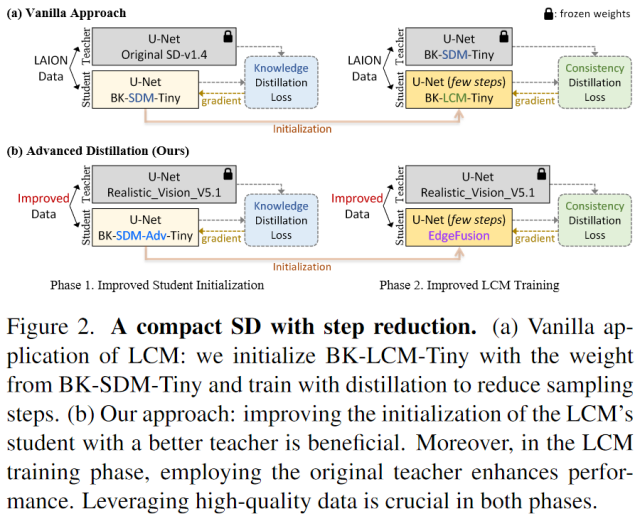
The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices.
Paper: https://arxiv.org/abs/2404.11925
This entry was edited (3 weeks ago)

Lemmy Tagginator
in reply to Even_Adder • • •New Lemmy Post: EdgeFusion: On-Device Text-to-Image Generation (https://lemmyverse.link/lemmy.dbzer0.com/post/18748939)
Tagging: #StableDiffusion
(Replying in the OP of this thread (NOT THIS BOT!) will appear as a comment in the lemmy discussion.)
I am a FOSS bot. Check my README: https://github.com/db0/lemmy-tagginator/blob/main/README.md
lemmy-tagginator/README.md at main · db0/lemmy-tagginator
GitHub